
Advanced Topics
Excel Collection Mapping
Example Model
Imagine a DataClass model with the classes Country, State and City, interrelated with Java collections:
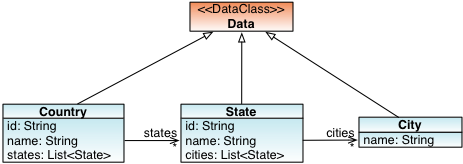
DataClasses
The model above is implemented with the following classes:
public class CountryData extends Data {
private String id;
private String name;
private List<StateData> states = new ArrayList<StateData>();
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<StateData> getStates() {
return states;
}
public void setStates(List<StateData> states) {
this.states = states;
}
}
public class StateData extends Data {
private String id;
private String name;
private List<CityData > cities = new ArrayList<CityData >();
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<CityData > getCities() {
return cities;
}
public void setCities(List<CityData > cities) {
this.cities = cities;
}
}
public class CityData extends Data {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Excel Sheet Mapping
Data of such a recursive collection mapping can be represented in Excel documents in the following manner:
- Create a 'country' tab with columns 'id', 'name' and 'states'
- In the country tab, create one row for each country, entering id and name data as usual
- For each country create a dedicated Excel tab that contains all states of the country, e.g. named 'states_de', with the columns 'id', 'name' and 'cities'
- In the country tab, declare the tab name containing the related data, entering 'tab:' followed by the tab name in the 'states' cell
- In the states tab, create one row for each state in the related country and create cities tabs for enumerating the cities
Excel Sheet Example
As an example one can map the following hierarchy
Germany (Country) +- Bayern (State) | +- München (City) | +- Regensburg (City) +- Hessen (State) +- Kassel (City) +- Wiesbaden (City) Italy (Country) +- Veneto (State) | +- Verona (City) | +- Venezia (City) +- Lomabardia (State) +- Milano (City) +- Bergamo (City)
using this Excel document structure (having all the tabs in the same Excel document):
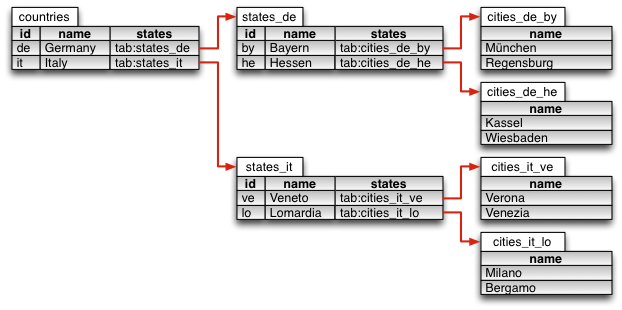
Data Consumption in a Test Case
When consuming this data in an AludraTest method like this:
@Test
public void testInbound(@Source(uri = "country.ent.xls", segment = "countries") CountryData country) {
System.out.println(country.getName());
}
The test method is executed twice, once with country Germany, once with country Italy having them wired with all their states and cities.
Skipping initial Rows in an Excel Sheet
When certain data sets of an Excel sheet require further examination, one can temporarily configure the test method to skip the first n rows, applying the annotation org.aludratest.annotations.test.Offset to the test method, for example for skipping the first 5 data rows:
@Test
@Offset(5)
public void test(@Source(uri = "myfile.ent.xls", segment = "mytab") MyData data) {
...
}
Generating Excel Documents
AludraTest provides a feature to generate Excel documents based on a test method's signature and annotations. There is a GUI and a command line version that allows you to create an Eclipse run configuration for generating Excel documents:
Excel Generation GUI
The Excel Generation GUI is started by launching the main class org.aludratest.app.excelwizard.ExcelWizard. It scans the current project folder for (already compiled) AludraTest test cases and displays them in a list.
Using a filter text, the user can filter the test cases by substring:
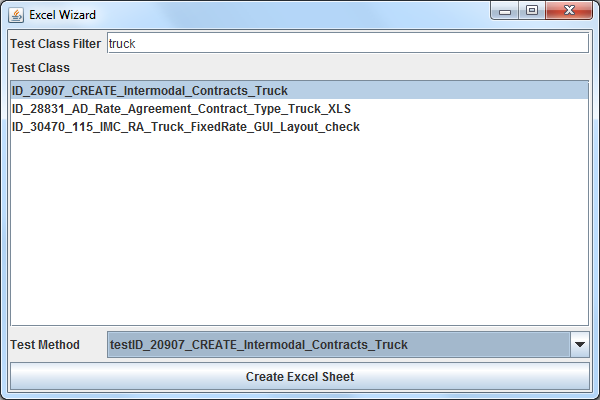
When selecting a test case from the list, the 'Test Method' dropdown box is updated to display all test methods that have @Source annotations.
The user can then select one and click 'Create Excel Sheet'. The wizard will then create an empty Excel sheets that contains a 'config' tab and data tabs that reflect the structure of the annotated method parameters:
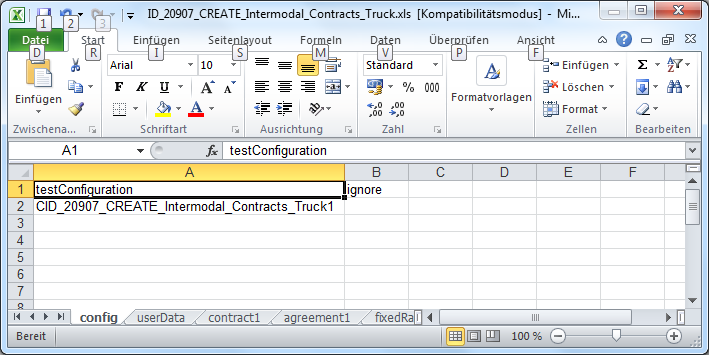
Excel Generation in Eclipse
For generating Excel documents in Eclipse, first create a "Java Application" run configuration that uses the project which contains the test class and set the main class to org.aludratest.app.excelwizard.CLIExcelCreator.
On second tab "Arguments", in the field 'Program Arguments' enter ${java_type_name}.
In order to execute the generator, select the test class in the Eclipse package explorer and start the new Run Configuration.